Alemanetik euskaratutako unitate fraseologikoen itzulpen-azterketa. Tesiaren nondik norakoak
Artikulu honetan, 2015eko martxoan defendatutako tesiaren nondik norakoak laburtuko ditugu. Tesiaren helburu nagusia unitate fraseologikoen (UF) itzulpena aztertzea izan da, alemanetik euskarara egin diren literatur itzulpenetan dauden itzulpen-portaerak (translation behaviours) deskribatu ahal izateko, bai zuzenean (edo aldez zuzenean) egin diren itzulpenetan bai zeharka egin direnetan ere. Itzulpen-azterketa, gainera, corpusean oinarritutakoa izan da. Gure kasuan horrek esan nahi du corpus digitalizatu, lerrokatu eta eleaniztuna (alemana-gaztelania-euskara) sortu dugula, Aleuska katalogoa oinarri hartuta, eta corpus horretatik erauzi ditugula aztergai izan diren UFak.
Sarrera
Tesiaren1 helburua alemanetik euskaratutako unitate fraseologikoen itzulpena aztertzea izan da, eta, artikulu honetan, horri dagozkion ideia garrantzitsuenak aipatuko ditut. Horretarako, tesiaren beraren banaketan oinarrituta, zazpi ataletan banatu dut artikulua: testuingurua eta helburuak, oinarri teorikoa, oinarri metodologikoa, aurretiazko azterketa, makro mailako azterketa, mikro mailako azterketa eta ondorioak.
Testuingurua eta helburuak
Ikerketa-lan hau ez da ezerezetik sortu. Aurrekari batzuk ditu -hala nola Barambonesen (2009), Manterolaren (2011) eta Zubillagaren (2013) tesiak-, eta horien eragina nabarmena da. Lan horietan, euskaratik edo euskarara egindako itzulpenak aztertu dituzte. Izan ere, ezin dugu ukatu itzulpen jarduerak euskara moduko hizkuntza gutxitu baten kasuan izan duen garrantzia, hizkuntzaren beraren garapena bultzatu duelako eta literatur sistema indartu duelako. Esan bezala, itzulpen horien azterketa izan da aipatu ditugun lanen xedea, eta nik ere bide horri heldu diot.
Testuinguru horretan, hizkuntza-konbinazioari dagokionez, Zubillaga da alemanetik euskararako itzulpenak aztertu dituena. Nire tesia Zubillagarena osatzera dator. Hona zein den bien arteko desberdintasun nagusia: hark generoaren ikuspegitik egin zuen azterketa, eta, nirean, berriz, abiapuntua hizkuntza-fenomeno bat da, unitate fraseologikoak (UFak hemendik aurrera), hain zuzen. Hizkuntza-unitate horiek aztertzeaz arduratzen diren ikerketa-lanak gero eta ugariagoak dira. Gainera, hainbat ikuspuntutatik eta hainbat hizkuntza-konbinaziotan aztertu izan dira. Alemana-euskarari dagokionez, aurkeztuko dugun tesi hau da unitate fraseologikoen itzulpena aztertuko duen lehen ikerketa-lana. Horrezaz gain, kalko fraseologikoen presentzia medio, sorburu-hizkuntzaren edo beste hizkuntza baten/batzuen interferentzia neurtzeko unitate interesgarriak izan daitezke itzulpengintzaren alorrean.
Tesia egin bitartean erantzun nahi izan ditugun galderak honako hauek dira:
- Zein joera daude, itzulpen-arau eta -legeei dagokienez, alemanetik euskararako UFen itzulpenean?
- Ba al dago alderik haur- eta gazte-literaturako (HGL) edo helduen literaturako (HL) testuak itzultzearen artean?
- Eta zuzenean edo zeharka itzultzearen artean?
- Euskara egoera diglosikoan dagoen hizkuntza gutxitua izateak nola eragiten dio itzulpen-jarduerari?
Oinarri teorikoa: Itzulpen ikasketa Deskribatzaileak eta fraselogia
Maila teorikoan, tesiaren abiapuntua Itzulpen Ikasketak izan dira, Itzulpen Ikasketa Deskribatzaileak, zehazki. Horregatik, marko teoriko-metodologiko horri dagozkion kontzeptuek berebiziko garrantzia izan dute tesian zehar. Gure kasuan, tesia marko horretan kokatzeak hau esan nahi du:
- Holmes-ek (1988) proposatutako eskeman, adar deskribatzailetik abiatu garela;
- xede-testu eta -kulturak osatzen dutela ardatza ––eta, beraz, zentzu horretan, produktuari bideratutako lana izango litzateke––, baina sorburu-testuarekiko harremana ere aintzat hartu dugula ––eta, zentzu horretan, prozesura bideratutakoa ere bada lana;
- datu enpirikoak corpusetik, testu errealetatik, erauzitakoak direla;
- jatorrizko eta xede-testuaren (edo testuen) arteko harremana definitzerako orduan, «ustezko» (assumed) kontzeptua ezinbestekoa izan dela. Horrek zuzeneko eta zeharkako testuen artean ñabardurak egon badaudela agerian utzi du;
- azkenik, bai itzulpen-arauak eta bai itzulpen-legeak aztertu direla, estandarizazioaren legea eta interferentziaren legea, alegia.
Baker-ek ez bezala, Touryk ez du unibertsalez (translation universals) hitz egiten, itzulpen- portaera erregularrak azaltzen dituzten legeez baizik. Hainbat faktorek baldintzatzen dituzte portaera horiek, eta, horregatik, probabilitate-izaera egokitzen die legeei: «if X, then the greater/the lesser the likelihood that Y» (Toury, 2012: 301).
Estandarizazioaren legearen arabera, itzultzerako orduan, jatorrizkoan dauden testu- harremanak aldatu egiten dira askotan ––are, batzuetan, ez dira kontuan hartzen––, eta xede- hizkuntzako aukeren artean ohiko(ago)ak direnen alde egiten da, xede-kulturako arauen alde, alegia: «in translation, textual relations obtaining in the original are often modified, sometimes to the point of being totally ignored, in favour of […] habitual options offered by a target repertoire» (Toury, 2012: 304). Bestalde, honako hau dio Touryk interferentziaren legearen inguruan: itzultzerako orduan, jatorrizko testuaren egiturari lotutako fenomenoak onartu egin ohi ditu itzultzaileak, eta horiek xede-testura pasatzen dira. Prozesu hori negatiboa izan daiteke ––xede-hizkuntzako ohituren aurka egiten denean–– baina baita positiboa ere.
Ezin izan ditugu estandarizazioaren legean eragina izan dezaketen aldagai guztiak kontuan hartu, baina ikusi dugu itzulpenen eta itzultzaileen estatusek itzulpenari eragiten diotela. Interferentziaren legeari dagokionez, makineria kognitiboa eta ingurumen sozio-kulturala aipatu ditugu aldagai posible gisa. Alemanetik euskararako itzulpenean, zeresan handia dutela ikusi dugu. Izan ere, elebitasun desorekatua/diglosikoa nagusitzen den ingurumen batean bizitzeak, eta, atzerriko hizkuntzaz gain, bi hizkuntza ama-hizkuntza mailan menperatzeak itzulpen- prozesuari eragiten diola ikusi dugu. Ondorioz, itzulpen-azterketa egiterako orduan, ezingo dugu ahaztu interferentziak egon daitezkeela.
Hainbat ikertzailek kritikatu egin dituzte aipatu ditugun lege horiek. Nire ustetan, baina, Touryk berak definitzen dituen moduan ulertzen baditugu, hots, izaera probabilistikoa duten ideia heuristiko gisa, itzulpen-legeen azterketatik lortutako emaitzek ekarpena egin diezaiekete Itzulpen Ikasketei. Horregatik, Tymoczkok (1998: 656) ez bezala, iruditzen zait merezi duela legeak aztertzea.
UFak direnez aztergai izan dugun hizkuntza-fenomenoa, tesian zehar zer diren eta zer ezaugarri dituzten aztertu dugu. Ikuspuntu historikotik deskribatu ditugunean, xede-kulturan jarri dugu bereziki arreta. Euskal fraseologian ekarpenak egin dituzten fraseologo eta paremiologo nagusiak eta haien lanak aipatu ditugu. Esate baterako, Izagirre (1981), Mokoroa eta Garatek izugarrizko bilketa-lanak egin zituzten. Gaur egun, hainbat ikuspuntutatik aztertu dira euskal fraseologismoak: itzulpenaren ikuspuntutik aztertu zituen Aierbek (2008), gaztelania-euskara hizkuntza-konbinazioan; Altzibar, García eta Alberdik (2010) euskal UFak prentsako testuetan nola erabiltzen diren aztertu dute; eta IXA taldeko zenbait kidek ikerketa-lanak egin dituzte (eta egiten dihardute) Hizkuntzaren Prozesamenduaren ikuspuntutik ––besteak beste, Urizar (2012) eta Gurrutxaga (2014).
Bestalde, UFak kontzeptualki deskribatu ahal izateko, jatorrizko hizkuntzaren inguruan egin diren ikerketak eta argitaratu diren monografiak aztertzea ezinbestekoa izan da. Eskuarki, hitz anitzeko unitate gisa definitzen dira, zeinak, neurri handiago edo txikiagoan, egonkorrak eta idiomatikoak diren. UFen izaera polilexikoari dagokionez, grafikoki hitz bakarra osatzen duten hitzak fraseologiara ekartzeko proposamenei erreferentzia egin diegu tesian. Gainera, badakigu hitz konbinazio hauek egonkorrak direla, baina hasieran pentsatzen zena baino aldaketa gehiago onartzen dituztela. Idiomatikotasuna, bestalde, zentzu hertsi eta malguan uler daiteke, eta azken ikuspegi hori da azken aldian gailentzen dena.
Ikerketaren alorrean, hizkuntza desberdinetako UFen erkaketa hizkuntzalaritza kontrastiboaren edo itzulpengintzaren ikuspuntutik egin daiteke. Nire abiapuntua bigarrena izan da, eta, horregatik, datuak ––kasu honetan, UFak–– txertatuta dauden testuinguruan aztertzea ezinbestekoa da.
UFen itzulpena aztergai izan duten lanen zenbaketa egite aldera, Wolfgang Mieder-en (2009) datu-base bibliografikoan «translation» etiketa duten lanak zenbatu ditugu. Emaitzak honako grafiko honetan ikus daitezke. Argi geratzen den moduan, 1970eko hamarkada amaieratik aurrera nabarmen hazi ziren UFen itzulpena aztertzeaz arduratzen ziren lanak.
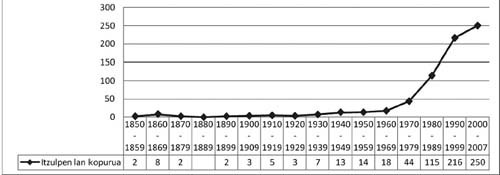
Garrantzitsua iruditzen zaigu aipatzea itzulpen-azterketa asko paradigma preskriptiboaren barruan kokatzen direla. Horrek esan nahi du itzulpen-lege inplizitu bat nagusitzen dela, zeinaren arabera A hizkuntza bateko UF bat beste UF baliokide batekin itzuli beharko litzatekeen B hizkuntzara, xede hizkuntzara. Lan honetan, Farø-k (2006) aipatzen duen dogma fraseologiko hori gainditu nahi izan dugu. Nola itzuli beharko litzatekeen aztertu baino gehiago, nola itzultzen den aztertu nahi izan dugu. Hori egin ahal izateko, corpus digitalizatu, lerrokatu eta eleaniztun batetik erauzitako datuak aztertu ditugu sistematikoki, COVALT ikerketa-taldeko2 kideek 2001. urtetik aurrera egin duten modu bertsuan.
Oinarri metodologikoa: Lambert eta van Gorp-en eredua eta corpusgintza
Lambert eta van Gorp-ek 1985. urtean proposatutako eredua izan da tesian garatutako metodologiaren ardatza, Itzulpen Ikasketa Deskribatzaileekin bat datorrelako, modu sistematikoan lan egitea ahalbidetzen digulako eta nork bere ikerketara moldatu dezakeen tresna heuristiko gisa funtzionatzen duelako (Lambert eta van Gorp, 1985: 45). Lau dira goitik beherako eskema malgu horren puntu nagusiak: aurretiazko azterketa, makro mailako azterketa, mikro mailako azterketa eta azterketa sistemikoa.
Bestalde, corpusean oinarritutako azterketa burutu dugunez, corpusgintza ezinbestean landu beharreko alorra izan da. 1967. urtean sortu zen lehen corpus elektronikoa, eta 90eko hamarkada da erreferentzia-corpus zabalen garaia. Lehen euskal corpusa, Orotariko Euskal Hiztegiaren testu-corpusa, 1984. urtekoa da, eta, Areta eta al. (2008) lanean aipatzen den moduan, datu horrek adierazten du euskara ez zela berandu iritsi corpusgintzara (2008: 79). Gaur egungo egoerari dagokionez, iruditzen zait euskal corpusen kalitatea eta aniztasuna direla azpimarratu beharrekoak; corpus elebakarrak (Web-corpusen Ataria3) kontsulta ditzake erabiltzaileak sarean, elebidunak (Web-corpusen Atariko corpus paraleloa4), eleaniztunak (Eroski Consumer Corpusa5), EHUskaratuak6), erreferentziazko gisa funtziona dezaketenak (Egungo Testuen Corpusa7), espezializatuak (Zientzia eta Teknologiaren corpusa8), estatikoak (Ereduzko Prosa Gaur9), monitoreak (Ereduzko Prosa Dinamikoa10), gaur egunekoak (orain arte aipatutakoak) edo hizkuntzaren bilakaera jasotzeko asmoa dutenak (XX. mendeko Euskararen Corpus Estatistikoa11), besteak beste.
TRALIMA-ITZULIK ikerketa-taldetik12 ekarpena egin nahi izan diogu euskal corpusen eremuari, eta zenbait doktoretza-tesiren baitan corpus digitalizatu, lerrokatu eta eleaniztunak sortzen aritu gara azken urteotan ––nire kasuan, AleuskaPhraseo corpusa, alemanetik euskarara itzulitako literatur testuz osatuta dagoena.
Aurretiazko azterketa: Aleuska katalogoa eta AleuskaPhraseo corpusa
Corpusa sortzen hasi baino lehen, beharrezkoa iruditzen zitzaigun alemanetik euskarara itzuli diren testuen katalogazio-lana egin, eta katalogo hori deskribatzea.
2003an ekin zion Ibon Uribarrik lan horri, Aleuska katalagoa13 sortzeari, eta, ondoren, Zubillagak (2013) HGLri zegozkion 2011 arteko sarrerak eguneratu zituen. Nik eguneratu dudan azpicorpusa HGL eta HLri dagokio, eta 2013. urtera bitartekoak bildu nituen. Katalogazio maila honetan, itzulpen-moduaren inguruko informazioa izan da biltzen zailena; hau da, zehaztea zuzenean alemanezko jatorrizkotik abiatu diren itzultzaileak, edo zeharka egin dituzten itzulpenok, zubi-hizkuntza batetik (edo batzuetatik) abiatuta. Garrantzitsua da azpimarratzea aurretiazko azterketa honetan bildutako datuak ez direla behin betikoak, eta makro eta mikro mailako azterketetatik lortutako emaitzetan oinarrituta, behin-behineko datu horiek berretsi, edo, osterantzean, egokitu egingo ditugula. Beste azterketa horiek beharrezkoak dira, bestalde, zuzenean/zeharka dikotomia hori zabaldu ahal izateko. Izan ere, argi geratu da tesian zehar itzulpenak ezin direla bi multzo trinkotan banatu.
Orotara eta gaur-gaurkoz, 710 sarrera biltzen dira Aleuska katalogoan. Testu-moten banaketa adierazten duen 2. irudian argi ikusten da HGL dela gehien itzuli den generoa. Ondoren, poesia daukagu, baina kontuan izan behar da katalogoko sarrera asko poema solteek osatzen dutela. HL eta saiakera antzera itzuli dira, eta, zalantzarik gabe, gutxien itzuli den generoa antzerkia da.
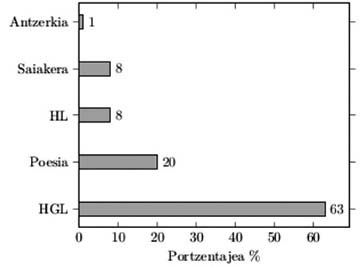
AleuskaPhraseo corpusa osatuko duten liburuak HGL eta HLkoak izango direnez, azpikatalogo hori deskribatu dugu xeheago. 504 testuk osatzen dute, eta, 2. irudiak argi adierazten duen moduan, bien arteko desoreka nabarmena da. Orotara, 126 jatorrizko egile eta 127 itzultzaile desberdinen lanak jasotzen dira azpikatalogoan. Denboran zehar izandako bilakaerari begiratzen badiogu, 80ko hamarkadatik aurrera egon zen gorakada iruditzen zaigu aipagarria. HGL eta HLko testuen alderaketari erreparatzen badiogu, paralelismoak daude itzultzaileei dagokienez. Itzultzaileak ez dira egile jakin batean espezializatzen, eta itzultzaile eta argitaletxeen artean ez ohi da loturarik egoten. Gainera, Pello Zabaleta eta Xabier Mendiguren oso itzultzaile emankorrak dira bai HGLn bai HLn, 80ko eta 90eko hamarkadetan, hurrenez hurren. Gerora, itzultzaile aniztasuna gailentzen da. Baina aldeak ere badaude narratibako testu-mota horien artean. Itzulpen modua aztertu dugunean ikusi dugu, esate baterako, HLan zuzenean egindako itzulpenak gailentzen direla (%61), eta, HGLn, berriz, zeharkakoak (%58). Bataren eta bestearen prestigioarekin izan dezake horrek zerikusia.
HGL-HL azpikatalogoa deskribatu eta gero, AleuskaPhraseo corpusa diseinatu eta sortzeari ekin genion. Corpusa diseinatzerako orduan, lau irizpide (kualitatibo) finkatu genituen. Lehenik, 1980. urtea eta gero argitaratutako itzulpenak hartu genituen aintzat. Bigarrenik, dagoeneko aipatu bezala, HGLko eta HLko testuz osatutako corpusa sortu genuen. Hirugarrenik, bai zuzenean eta bai zeharka itzulitako testuak aukeratu genituen, eta, azkenik, aniztasuna bermatu genuen sorburu- eta xede-egileei dagokienez; izan ere, gure asmoa ez zen sorburu- edo xede-egile jakin baten lanak eta itzulpenak aztertzea.
Behin testuak aukeratuta, corpusa bera sortzeari ekin genion. Horrek esan nahi du corpusa osatzen duten 110 testuak digitalizatu, garbitu, etiketatu eta lerrokatu egin genituela, gero bilaketak modu sistematikoan egin ahal izateko. Digitalizazioa eskuz egin beharreko prozesua izan da, baina beste pauso guztiak burutu ahal izateko, TRACEaligner programa erabili dugu, UPV/EHUko Itzulpengintza eta Interpretazioa jakintza-arloaren baitan dauden ikerketa- proiektu (TRACE) eta -taldeei (TRALIMA-ITZULIK) esker sortu dena14. AleuskaPhraseo corpusa sortzeko erabili genuena TRACEaligner-en 2.0 bertsioa izanagatik, hemen aurkeztuko duguna azken bertsioa izango da, 3.0, azken hori izango delako hemendik aurrerako lanetan erabiliko duguna.
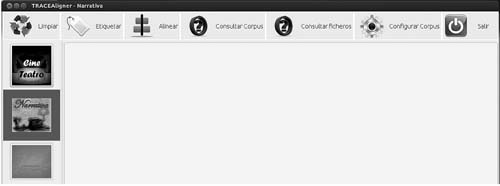
TRACEaligner programaren interfazea da 3. irudian ikus daitekeena. Ezkerraldeko zutabean testu-mota aukeratu daiteke (ikus-entzunezkoa/antzerkia, narratiba eta poesia), eta, goiko aldean, programak dituen aukerak agertzen dira; besteak beste, testuak garbitu, etiketatu, lerrokatu eta corpusean bilaketak egin. Testuek izan ditzaketen formatu-erroreak «garbitu» ahal izateko, TXT fitxategiak sortu behar dira. Ondoren, etiketatzeko, programa TXT horietatik abiatzen da, eta XML fitxategiak sortzen ditu, zeinak bi zati nagusitan banatzen diren: metadatuak (non testuaren inguruko informazioa jasotzen den, hala nola egilea, itzultzailea, generoa, itzulpen-modua…) eta testua bera. Testu hori, era berean, esaldi eta paragrafotan banatuta dago etiketa bidez. Hurrena, testuak lerrokatu behar dira; hau da, jatorrizko esaldi bakoitzari dagokion xede-esaldia egokitu behar zaio. Behin testuak lerrokatuta, datu-base moduko bat sortuko dugu, eta bilaketak egiteko gai izango gara. 4. irudian, esaterako, bilaketa baten emaitza ikus dezakegu.
Labur azaldu badugu ere, corpusa sortzeari denbora dezente eskaini diogu; prozesu luzea izan da. Gainera, corpusa sortu bitartean TRACEaligner programa bera garatzen joan gara informatikariaren, Iñaki Albisuaren, laguntzaz15. Gaur egun dauden corpusekin alderatuta, 3,5 milioi hitzeko corpusak nahiko txikia dirudi lehen begiratuan, baina, alde batetik, kontuan hartu behar da aipatu berri duguna, eta, bestalde, gure helburuak betetzeko nahikoa handia dela iruditzen zaigu. 1. taulan, corpusak dituen beste hainbat ezaugarri jaso ditugu: zuzenean eta zeharka itzuli diren zenbat lan jasotzen dituen corpusak eta sorburu- eta xede-egile desberdinen kopurua.
|
Itzulpen-modua
|
Egileak
|
Hitz kopurua
|
|||||
| Zuzenean | Zeharka | Sorburu-egile | Xede-egile | Alemana | Euskara | Gaztelania | |
| HL |
19
|
5
|
17
|
15
|
1.120.534
|
935.530
|
198.274
|
| HGL |
15
|
9
|
13
|
16
|
593.871
|
512.204
|
166.860
|
| Guztira |
34
|
14
|
30
|
28
|
1.714.405
|
1.447.734
|
365.134
|
Makro mailako azterketa: paratestuen eta paraitzulpenen azterketa
Makro mailako azterketan, paratestuak eta paratestu horien itzulpena analizatu dugu, eta, lortutako emaitzetan oinarrituta, behin-behineko ondorio batzuk atera ditugu, batez ere itzulpen-moduari eragiten diotenak.
Genette-n (1987) arabera, elementu paratestualak bi multzotan banatzen dira, elementuen kokapena zein den: peritestuak, testuan bertan aurkitzen direnak (izenburua, hitzaurreak, hitz- atzeak, irudiak…), eta epitestuak, testuarekiko zentzuzko distantzia batera kokatuak (kritikak, elkarrizketak, gutunak…). Peritestu eta epitestuen batuketaren emaitza da paratestua.
Gure corpuseko testuen kasuan ondorioztatu dugu itzultzailearen ikusgarritasuna nabarmenagoa dela HLko itzulpenetan, kasuen %75ean azalean agertzen delako itzultzailearen izena. HGLn, berriz, ez dugu kasu bakar bat ere aurkitu. Kontuan hartzekoa da, gure corpuseko HLko liburu batzuk Literatura Unibertsala bildumakoak direla, eta gure corpusean jaso ditugun bilduma horretako liburu guztiek daramatela itzultzailearen izena azalean. Esan dezakegu eredu bat sortu dela bilduma horri esker, eta beste argitaletxe batzuek eredu horri jarraitzen diotela, HLn, behinik behin.
Itzulpen-prozesuaren ikusgarritasunari erreparatzen badiogu, agerian geratzen da kasu gehientsuenetan (48tik 42tan), ustez zeharka itzulitakoak barne, alemanezko jatorrizko izenburua paratestuetan agertzen dela. Esan dezakegu, modu horretan, zeharka itzuli diren testuen zeharkakotasun izaera hori ezkutatzeko ahalegina dagoela. Aitzitik, sorburu-hizkuntza, alemana, lau kasutan besterik ez da berariaz zehazten. Zubi-bertsioen inguruko edizio datuen inguruko informazioa, zeharkakotasunaren adierazle izan daitekeena, bestalde, HGLko testuetan bakarrik jasotzen da, eta, gure kasuan, bost testutan besterik ez. Oro har, esan dezakegu paratestu mailako elementuek ez dutela itzulpen-prozesuaren inguruko informazio horren fidagarria ematen. Horregatik, epitestuetara ere jo genuen; hots, itzultzaileekin harremanetan jarri ginen kasu batzuetan, eta berariaz galdetu genien ea alemanetik zuzenean edo zubi-bertsio batetik (edo batzuetatik) abiatuta itzuli zituzten lanok.
Ondoren, Garrido Vilariñok (2011) proposatutako kontzeptu batean oinarrituta, paratranslation delakoa, paratestuen itzulpena aztertu genuen; alegia, liburuen izenburuak nola itzuli diren ikusi genuen, liburu barruko atalen itzulpena ere deskribatu genuen, eta liburuetako sorburu- eta xede-azalak ere alderatu genituen. Kasu batzuetan, makro mailako itzulpen-azterketa horretan ikusi dugu ustez zuzenean itzuli diren (batez ere) HGLko testu batzuen kasuan alemanezko jatorrizkoa ez den beste testuren batek eragina izan duela euskarazko itzulpenean.
Hori gertatzen da, esate baterako, bi liburu hauekin: Jojo, pailazo baten historia eta Ingeles bat etxean. Gaztelaniazko bertsioetako izenburuak, hurrenez hurren, hauexek dira: Jojo, historia de un saltimbanqui eta Intercambio con un inglés. Berdin-berdinak ez izan arren, jatorrizkoak (Das Gauklermärchen eta Das Austauschkind) ez dituzten hitzak partekatzen dituzte euskarazko eta gaztelaniazko itzulpenek, hala nola «Jojo» eta «ingeles». HLko beste liburu baten kasuan, Hildakoek ez dute hitz egiten, itzultzaileak esan zigun zuzenean alemanetik itzuli zuela, baina gaztelaniazko eta ingelesezko bertsioak ere izan zituela kontutan. Ipuinetako baten izenburuaren itzulpenean sumatu dugu alemanezkoa ez den beste bertsio baten interferentzia: Ekintza onak, diskrezioz eta fede onez eginak ipuinean, hain zuzen. Izan ere, gehiago gerturatzen da gaztelaniazko bertsiora (Obras de caridad, con discreción y de buena fe) alemanezkora baino (Wohltaten, still und rein gegeben).
Ondorioz, ñabardura horiek guztiak jasotzen dituen sailkapen malguago bat behar dugu itzulpen-prozesuan parte hartzen duten testuen arteko harremana xeheago deskribatu ahal izateko. Horretarako, ñabardura horiek guztiak hobeto islatzeko, «zuzeneko» eta «zeharkako» etiketez gain, «aldez zuzenekoa» eta «zeharkako konpilatua» terminoak gehitu ditugu makro mailako azterketa egin eta gero.
Mikro mailako azterketa: somatismoen eta binomioen itzulpena
Testu-azterketa mailan, bi UF mota izan ditugu aztergai: somatismoak eta binomioak. Horrela, bi azterketetatik lortutako emaitzak alderatzeko aukera izan dugu. Bestalde, corpusean bilaketak egiterako orduan, ez gara bakarrik sorburu-testuetatik abiatu, ohikoa den legez; euskal itzulpenetatik abiatutako bilaketak ere egin ditugu. Hala, IIDen baitan nagusitzen den joerari (target-orientedness delakoari) jarraituz, xede-testuan jarri dugu arreta.
UF-erauzketak egiterako orduan, ez dugu berdin jokatu somatismo eta binomioen kasuan. Hitz-zerrendak izan dira abiapuntua lehenengoen kasuan. 2. taulan ikus daitekeen moduan, AleuskaPhraseo corpusean maizen erabiltzen diren izenen artean daude gorputz-atalak, bai alemanez bai euskaraz. Alemanezko Hand (esku) eta euskarazko esku oso ohikoak direnez bi hizkuntzetan, Hand edo Händ-ekin eta esku-rekin hasten diren hitz guztiak (testuingurua barne) erauzi genituen corpusetik. Ondoren, banan-banan aukeratu genituen Hand eta esku-rekin osatutako somatismoak, eta beste emaitza guztiak baztertu egin genituen.
| Izena (DE) |
Maiztasuna
|
Izena (EU) |
Maiztasuna
|
| Hand (esku) |
2.664
|
buru |
4.366
|
| Herr |
2.387
|
ama |
3.861
|
| Mann |
2.177
|
etxe |
3.209
|
| Mensch |
2.132
|
esku |
3.068
|
| Frau |
1.980
|
hitz |
2.930
|
| Auge (begi) |
1.878
|
gizon |
2.775
|
| Haus |
1.786
|
urte |
2.730
|
| Kopf (buru) |
1.598
|
gauza |
2.314
|
| Mutter |
1.563
|
begi |
2.216
|
| Leben |
1.562
|
aurpegi |
1.633
|
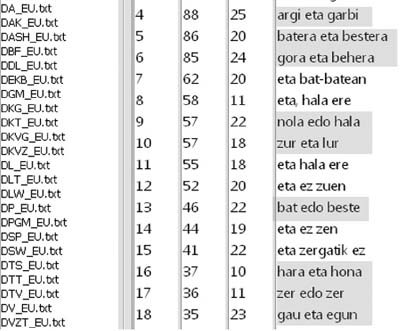
Binomioei dagokienez, corpusak ustiatzeko tresna bat erabili genuen, Antconc16 programa, eta gutxienez bi aldiz agertzen diren hiru-gramak erauzi genituen AleuskaPhraseo corpusetik. 5. eta 6. irudietan ikus daiteke euskarazko ––argi eta garbi (88), batera eta bestera (86), gora eta behera (85), nola edo hala (57), zur eta lur (57), bat edo beste (46), hara eta hona (37), zer edo zer (36), gau eta egun (35)–– eta alemanezko ––ab und zu (54), ganz und gar (50), (von) Zeit zu Zeit (49)–– binomio batzuen maiztasuna. Erauzitako binomio kopuru handia dela-eta, formula estatistiko bat erabili genuen lagin adierazgarri batekin lan egin ahal izateko.
Behin aztergai izango ziren UFak aukeratu eta erauzita, horien itzulpena aztertu genuen. Horretarako, Marcok (2008) proposatutako itzulpen-tekniken zerrenda batetik abiatu ginen, eta, gure beharren arabera, moldaketa batzuk egin genizkion hasierako zerrenda horri. Hauek dira itzulpen-azterketan erabili genituen itzulpen aukerak:
- UF-antzeko UFa
- UF-UF desberdina
- UF-UFrik ez
- UF-kopia zuzena
- UF-zeharkako kopia
- UF-beste baliabide erretoriko bat
- UF-Ø
- UFrik ez-UF
- UFrik ez-zeharkako kopia
- Ø-UF
Zuzeneko eta zeharkako kopien arteko bereizketa hori izan da Marcoren zerrendari egin genion egokitzapenik nabarmenena. Zuzeneko kopien kasuan, jatorrizko testuko interferentzia izango genuke (testu interferentzia, beraz), eta zeharkakoek, berriz, jatorrizkoa ez den beste hizkuntza edo testu baten eragina adieraziko lukete. Garrantzitsua iruditu zaigu bien arteko bereizketa hori egitea, alemanetik zuzenenean itzultzen denean ere, beste hizkuntza baten interferentzia-zantzuak aurkitu baititugu euskal itzulpenetan. Kasu horiei, interferentzia kognitibo deitu diegu, interferentzia ez delako (ustez) testu batek eragindakoa, itzultzailearen buruan gertatutakoa baizik.
Jarraian, itzulpen-azterketatik lortutako emaitza adierazgarrienak aipatuko ditugu. Lehenik, abiapuntua sorburu-testua izan denean lortutako emaitzak jasoko ditugu, eta, ondoren, xede-testuetan jarriko dugu arreta.
Proportzionalki, UF gehiago erauzi ditugu HLko testuetatik. Horrek adieraz dezake, HGLko testuen aldean, hizkuntza jasoagoa erabiltzen dela.
Eskuarki, itzulpen-aukera ohikoena, bai somatismo bai binomioen kasuan, UF bidezko itzulpena da, eta ohikoagoa somatismoen itzulpenean (%61,26 eta %50,64, hurrenez hurren). Seguruenik sistema-mailan alemanez eta euskaraz bat datozen somatismo gehiago egongo dira binomioak baino, eta horrek eragina izan dezake lortu ditugun emaitzetan. Nolanahi den, portzentajeak altuak dira, eta datu horrek erakusten du badagoela ahalegin bat xede-testuetan jatorrizko testuen izaera fraseologikoa gordetzeko.
Somatismo eta binomioen artean aurkitu dugun beste desberdintasun bat omisio eta zeharkako kopiei dagokie. Binomioen kasuan, ez dugu zeharkako kopiarik aurkitu, baina omisio bidezko itzulpena askoz ohikoagoa da binomioen kasuan (%6,69) somatismoen kasuan (%0,33) baino. Azken finean, errazagoa da karga semantiko horren handia ez duten hitz-konbinazioak itzulpen-prozesuan desagertzea.
Zeharkako itzulpenei dagokienez, bai somatismo bai binomioen itzulpenetan ikusi dugu gaztelaniazko zubi-bertsiotik aldentzeko eta euskaraz hitz-konbinazio jatorragoak sortzeko joera dagoela. Era berean, lehen begiratuan alderantzizkoa dirudien joera ere aurkitu dugu, gaztelaniatik euskarara egindako itzulpenetan, kopia bidez itzulitako kasu batzuk aurkitu baititugu. Ondorioz, onargarritasunerako joera eta testu jatorrak sortzekoa ez litzateke kasu horietan beteko. Aipatu beharra dago, baina, adibide horiek 80ko eta 90eko hamarkada hasierako testuetan aurkitu ditugula. Beraz, argudia liteke denbora pasatu ahala itzultzaileen jarrera ere aldatzen joan dela.
HLko edo HGLko testuak itzultzearen artean, bestalde, aldeak badaudela ikusi dugu. Batez ere binomioen itzulpen-azterketan atentzioa eman digu UFak erabili arren xede-testuetan, ez direla beti forma estandarrenak aukeratzen, eta joera hori nabarmenagoa dela HLko testuen kasuan. Von Zeit zu Zeit ("noizean behin") binomioaren itzulpenean, esate baterako, horixe bera da ikusi duguna: itzulpen-aukera ugari jaso ditugu, baina corpuseko (ETC corpuseko, hain zuzen) agerpen-maiztasunen arabera gutxien erabiltzen direnak (esate baterako, alditik aldira edo noizetik noizera) HLko itzulpenetan bakarrik aurkitu ditugu. Hori dela eta, aipatu dugu itzultzaileek ahalegina egiten dutela testu jasoak sortzeko, eta joera hori nabarmenagoa dela HLko testuen itzulpenean.
Sorburu-testuetan UFrik ez egonagatik, euskarazko itzulpenetan UFak erabili direneko kasuen portzentajeak altuak dira bai somatismo (% 69,19) bai binomioen (% 77,94) kasuan. Batzuetan, aukera logikoena iruditu zaigu euskal UF horiek erabiltzea itzulpenetan, oso ohikoak baitira. Baina, besteetan, ahalegin berezia egin dela iruditzen zaigu UF horiek xede-testuetan txertatzeko. Inpresioa daukagu UF horien erabileraren bidez konplexutasun jakin bat gorde nahi dela xede-testuetan edo jatorrizkoak baino testu adierazkorragoak sortu nahi direla. Touryk (2012) dioenari jarraiki, xede-sistema ahula denean, badago UFrik ez-UF (eta Ø-UF) itzulpen-aukerak agertzeko joera, eta hori xede-sistemaren ahultasuna konpentsatzeko ahalegin gisa uler daiteke (2012: 140).
|
Sorburu-testua
|
Xede-testua
|
|
Ich war sprachlos. (HFde)
|
Hitzik gabe ni, zur eta lur. (HFeu)
|
|
Sorburu-testua
|
Xede-testua
|
| Frühstens morgen würde er sich zur grünen Geisterbahn schleichen können. (GGde) | Biharamuna arte gutxienez ezingo zuen sorgin-trena ikustera joan. Nola edo hala…ezkutuan…Hori espero zuen! (GGeu) |
Bilaketak xede-testuetatik abiatuta egin ditugunean ere, ez dugu zeharkako kopiarik aurkitu binomioen itzulpen-azterketan, baina bai somatismoen kasuan (%3,37). Ikus dezagun adibide bat:
|
Sorburu-testua
|
Xede-testua
|
| Wat ick nötig habe, kann ick mir jeden Tag an die Finger abzählen. (BAde) | Nik zer behar dudan, eskuko hatzekin konta zezakeat. (BAeu) |
Alemanez, sich etwas an den Fingern abzählen können UFa daukagu. Hitzez hitz 'zerbait hatzekin kontatu ahal izan' esan nahi du, eta RAE hiztegian agertzen den gaztelaniazko contar algo con los dedos de una mano UFaren oso antzekoa da. Iruditzen zaigu gaztelaniazko UF horrek eragina izan duela euskarazko itzulpenean, eskuko hatzekin kontatu somatismoa contar algo con los dedos de una mano-ren hitzez-hitzezko itzulpena baita. Interferentzia kognitibo gisa identifikatu dugun hori izan daiteke kasu honetan gertatzen dena.
Ondorioak: ekarpenak eta etorkizuneko urratsak
Alemana-euskara hizkuntza konbinazioan unitate fraseologikoen itzulpena aztertzeko lehen saiakera da tesi hau. UFen itzulpena aztertu izan da beste hizkuntza-konbinazio batzuetan, baina ez dago aurrekaririk alemana-euskara konbinazioan.
Maila teorikoan, Euskal Itzulpen Ikasketen egoera kontuan hartuta, garrantzitsua iruditu zaigu tesia Itzulpen Ikasketa Deskribatzaileen markoan kokatzea. Behin datuak lortu eta deskribatu ondoren, gai izango gara adar teoriko eta aplikatuan, itzulpenaren irakaskuntzan, esate baterako, ekarpenak egiteko.
Lambert eta van Gorpen kiribil formako eskeman oinarrituta egin diren urratsak metodologia enpirikoaren isla dira. Eskema hori aplikatzeak esan nahi du ziklo osoa egiten saiatu garela, testuinguru orokorretik testurainokoa.
Neurri handi batean eman diren pauso horiei esker, sorburu-, xede- eta zubi-bertsioen arteko harremana nahiko modu xehean deskribatu ahal izan dugu. Katalogo mailan biko kategorizazioaz baliatu garen arren, azterketan aurrera egin ahala ikusi dugu eskema malguago bat behar dela. Gure beharrei erantzuteko, bi termino berri proposatu ditugu: aldez zuzenekoa eta zeharkako konpilatua.
Metodologikoki, COVALT ikerketa-taldeak bide berritzaile bat ireki zuela iruditzen zaigu, eta gu oso antzeko bidea egiten ari garela corpusean oinarritutako euskal itzulpen-ikasketen baitan. Corpusari lotuta, epe laburrera bete nahi diren helburuak hiru dira: zubi-bertsioak sistematikoki gehitzea, TRACEaligner 3.0 bertsioa doitzen jarraitzea eta corpusa lematizatzea.
Epe luzera begira, oso interesgarria izango litzateke corpusean oinarritutako alemana-euskara (gaztelania) hiztegi fraseologikoa sortzen hasteko lehen urratsak egitea.
Itzulpen-azterketari erreparatzen badiogu, sorburu-testuetatik abiatuta egiten den itzulpen- azterketa tradizionala egiteaz gain, gure azterketa bikoitza izan da, xede testuetatik ere abiatu garelako. Horrela, «sorburu-testu xede-testu» ikuspegi tradizionala gainditu dugu.
Itzulpen-arauei dagokienez, itzulpen-portaera erregularrak identifikatu ditugu, hala nola onargarritasunerako joera handiagoa dela zeharkako itzulpenetan zuzenekoetan baino, edo zeharkako testuetan zubi-bertsiotik aldentzeko joera.
Emaitza interesgarriak lortu ditugu, bestalde, itzulpen-legeen azterketatik. Estandarizazioaren legeari dagokionez, aipatu dugu UFen erabilera ez datorrela beti bat hizkuntzaren erabilera ohiko edo konbentzionalarekin. Batzuetan, esate baterako, eguneroko hizkuntzan horren ohikoak ez diren UFen erabileraren bidez, itzultzaileek ahalegin berezi bat egiten dute diskurtso literario jakin bat sortzeko. Horregatik, hemendik aurrera, estandarizazioa neurtzeko beste parametro batzuk erabili beharko genituzkeela iruditzen zaigu. Bestalde, interferentzia neurtzeko unitate aproposak dira unitate fraseologikoak. Gure kasuan, zuzeneko eta zeharkako kopien emaitzek lege hau hizkuntza-konbinazio honetan nola gauzatzen den ikusten lagundu digute. Lege proposamen bat egitera ere ausartu gara. Honela dio: A hizkuntza batetik B hizkuntza gutxitu batera itzultzerako orduan, B hizkuntza egoera diglosikoan baldin badago eta C hizkuntza nagusi batekin elkarrekin bizi bada, orduan C hizkuntzaren interferentzia egon daiteke B hizkuntzan.
Agerian geratu da hizkuntzaren kanpotiko aldagaien ––besteak beste, kultur testuinguruaren eta egoera soziolinguistikoaren–– garrantzia tesian zehar: corpusa diseinatzerako orduan, testu-azterketa egiterako orduan eta abar. Euskararen egoera aintzat hartu gabe, ez genuke sortu dugun corpus eleaniztuna sortuko, edo ezingo genituzke emaitza asko ulertu. Hain zuzen emaitzen interpretazio zehatzagoa egite aldera, etorkizunera begira, interesgarria izango litzateke corpusetik lortutako datuak beste ikuspegi batzuetatik lortutakoekin osatzea, itzulpen- ikasketa kognitiboetatik eta hizkuntzalaritza aplikatutik lortutakoekin oro har.
Bibliografia
AIERBE, Axun (2008). "La traducción a la lengua vasca de las unidades fraseológicas especializadas del lenguaje administrativo", in González, María Isabel (arg.) A Multilingual Focus on Contrastive Phraseology and Techniques for Translation, Hamburg: Kovač, 27-44 or.
ALTZIBAR, Xabier, GARCÍA, Julio, ALBERDI, Xabier (2011). "Calcos fraseológicos en el euskera de los medios de comunicación", in Luque, Lucía; Pamies, Antonia eta Pazos, José Manuel (argk.) Multi-Lingual Phraseography: Second Language Learning and Translation Applications, Baltmannsweiler: Schneider, 215-224 or.
ARETA, Nerea; GURRUTXAGA, Antton eta LETURIA, Igor (2008). "Begiratu bat corpus-baliabideei", BAT Soziolinguistika aldizkaria 62.
BARAMBONES, Josu (2009). La traducción audiovisual en ETB-1: Estudio descriptivo de la programación infantil y juvenil, UPV/EHU. http://www.argitalpenak.ehu.es/p291-content/eu/contenidos/informacion/se_indice_tescspdf/eu_tescspdf/adjuntos/TESIS_JOSU_BARAMBONES.pdf.
Farø, Ken (2006). "Dogmatismus, Skeptizismus, Nihilismus und Pragmatismus bei der Idiomübersetzung: Grundfragen zu einer idiomtranslatorischen Theorie", in Häcki, Annelies eta Burger, Harald (argk.) Phraseology in Motion I. Methoden und Kritik, Baltmannsweiler: Schneider, 189-202 or.
GARATE, Gotzon (1998). 27.173 Atsotitzak, Refranes, Proverbes, Proverbia, Lasarte-Oria: BBK Fundazioa.
GARRIDO VILARIÑO, Xoán Manuel (2011). "The paratranslation of the works of Primo Levi", in Federici, Federico M. (arg.) Translating Dialects and Languages of Minorities. Challenges and Solutions, Oxford et al.: Peter Lang, 65-88 or.
GURRUTXAGA, Antton (2014). Idiomatikotasunaren karakterizazio automatikoa: izena+aditza konbinazioak, UPV/EHU.
IZAGIRRE, Koldo (1981). Euskal lokuzioak. Espainolezko eta frantsesezko gida-zerrendarekin, Donostia: Hordago.
HOLMES, James S. (1988): "The Name and Nature of Translation Studies", in J. Holmes, Translated! Papers on Literary Translation and Translation Studies, Amsterdam: Rodopi, 67-80 or.
LAMBERT, Jose, eta VAN GORP, Hendrik (1985). "On Describing Translations", in Hermans, Theo (arg.) The Manipulation of Literature: Studies in Literary Translation, London/Sydney: Croom Helm.
ANTHONY, Laurence (2014). Antconc (3.4.3 bertsioa), Tokyo: Waseda Unibertsitatea.
MANTEROLA, Elizabete (2011). Euskal literatura beste hizkuntza batzuetara itzulia. Bernardo Atxagaren lanen itzulpen moten arteko alderaketa, UPV/EHU. http://www.ehu.es/argitalpenak/images/stories/tesis/Humanidades/ELIZABETE_MANTEROLA.pdf.
MARCO, Josep (2008). "In my mind's eye: análisis traductológico de algunos fraseologismos prototípicos en el contexto del corpus COVALT (Corpus Valencià de Literatura Traduïda)", Actas del III Congreso Internacional de la Asociación Ibérica de Estudios de Traducción e Interpretación, Bartzelona: PPU, 251-262 or.
MARCO, Josep (2009). "Normalisation and the Translation of Phraseology in the COVALT Corpus", Meta 54, 842-856 or.
MARCO, Josep (2013). "La traducció de les unitats fraseològiques de base somàtica en el subcorpus anglès-català", in Bracho, Llum (arg.) El corpus COVALT: un observatori de fraseologia traduïda, Aachen: Shaker, 163-215 or.
MIEDER, Wolfgang (2009). International Bibliography of Paremiology and Phraseology, Berlin; New York: Walter de Gruyter.
MOKOROA, Justo Mari (1990). "Ortik eta emendik": repertorio de locuciones del habla popular vasca, oral y escrita, en sus diversas variedades, Bilbo: Labayru.
OSTER, Ulrike eta VAN LAWICK, Heike (2013). "Anàlisi dels somatismes del subcorpus alemany-català", in Bracho, Llum (arg.) El corpus COVALT: un observatori de fraseologia traduïda, Aachen: Shaker,267-294 or.
TOURY, Gideon (2012). Descriptive Translation Studies and Beyond, Amsterdam: John Benjamins.
TYMOCZKO, Maria (1998). "Computerized Corpora and the Future of Translation Studies", Meta 43, 652-660 or.
URIZAR, Ruben (2012). Euskal lokuzioen tratamendu konputazionala, UPV/EHU.
ZUBILLAGA, Naroa (2013). Alemanetik euskaratutako haur eta gazte literatura: zuzeneko nahiz zeharkako itzulpenen azterketa corpus baten bidez, UPV/EHU. http://www.ehu.es/argitalpenak/images/stories/tesis/Humanidades/8670ZubillagaEU.pdf.
Corpuseko testuak:
BAde = DÖBLIN, Alfred (1929). Berlin Alexanderplatz: Die Geschichte vom Franz Biberkopf, Berlin: Fischer.
BAeu = DÖBLIN, Alfred (2000). Berlin Alexanderplatz: Franz Biberkopfen istorioa [itzul. Antton Garikano], Euba: Ibaizabal.
ENDE, Michael (1982). Das Gauklermärchen, Stuttgart: Thienemann.
ENDE, Michael (1995). Jojo, pailazo baten historia, zazpi agerraldiko antzerkia, hitzaurrea eta hitzatzearekin [itzul. Xabier Mendiguren], Bilbo: Desclée De Brouwer.
ENDE, Michael (1986). Jojo, historia de un saltimbanqui [itzul. Flora Casas], Madril: Debate.
GGde = BREZINA, Thomas (1995). Grüße aus dem Geisterschloss, München: Bertelsmann.
GGeu = BREZINA, Thomas (2001). Diosalak espirituen gaztelutik [itzul. Xabier Mendiguren], Bilbo: Desclée De Brouwer.
GGes = BREZINA, Thomas (1996). Saludos desde el castillo de los espíritus [itzul. José Antonio Santiago], Madril: SM.
HFde = FRISCH, Max (957). Homo Faber: Ein Bericht, Frankfurt am Main: Suhrkamp.
HFeu = FRISCH, Max (2001). Homo Faber [itzul. Joxe Austin Arrieta], Donostia: Elkarlanean.
NÖSTLINGER, Christine (1982). Das Austauschkind, Weinheim: Beltz & Gelberg.
NÖSTLINGER, Christine (1991). Ingeles bat etxean [itzul. Xabier Mendiguren], Lizarra: Elkar.
NÖSTLINGER, Christine (1986). Intercambio con un inglés [Luis Pastor], Madril: Espasa- Calpe.
SCHNITZLER, Arthur (2009). Hildakoek ez dute hitz egiten [itzul. Ainhoa Irazustabarrena], Irun: Alberdania.
1. Tesi hau TRALIMA/ITZULIK (GIC12/197, UPV/EHU) ikerketa-taldearen barruan kokatzen da, eta, lanaren lehen aldian, Eusko Jaurlaritzako Hezkuntza, Unibertsitate eta Ikerketa Sailaren laguntza jaso zuen.
2. Jaume I unibertsitateko Josep Marco eta Heike van Lawick dira, bestea beste, COVALT (Corpus Valencià de Literatura Traduïda) ikerketa-taldeko kide. 2001. urtetik, COVALT corpusa sortu eta aztertzea izan da taldearen helburua. Corpus horretan oinarrituta, alemanetik eta ingelesetik katalanera itzulitako UFen inguruko hainbat azterketa egin dituzte (esate baterako, Marco 2008, 2009, 2013, eta Oster eta van Lawick 2013).
3. http://webcorpusak.elhuyar.org/cgi-bin/kontsulta.py?mota=arrunta
4. http://webcorpusak.elhuyar.org/cgi-bin/kontsulta2.py?mota=arrunta
5. http://corpus.consumer.es/corpus/
6. http://ehuskaratuak.ehu.eus/kontsulta/
8. http://www.ztcorpusa.net/aurkezpena.htm
9. http://www.ehu.eus/euskara-orria/euskara/ereduzkoa/
10. http://www.ehu.eus/eu/web/eins/ereduzko-prosa-dinamikoa-epd-
11. http://xxmendea.euskaltzaindia.eus/Corpus/
12. http://www.ehu.eus/tralima/inicio_eus.php
13. Aurki aukera egongo da katalogoa sarean kontsultatzeko: http://www.ehu.eus/tralima/catalogos_eus.php
14. Merkatuan dauden beste tresna batzuk erabil genitzakeen, egia da, baina gure lehentasuna bi hizkuntza baino gehiago aldi berean lerrokatuko zituen tresnarekin lan egitea zen, eta ez genuen gure beharretara behar bezala egokitzen zen ezer aurkitu.
15. Ezinbestekoa izan da informatikariaren eta gure arteko elkarlana. TRACEaligner sortu izan ez balu, corpusari ez geniokeen horrenbesteko etekina aterako. Beraz, nire esker ona adierazi nahiko nioke Iñaki Albisuari, egindako lan guztiagatik.


